|
I am a senior undergraduate student at the University of Science and Technology of China. I used to be a summer intern working at Stanford University on 3D object grounding. I am also fortunate to work with Prof. Tat-Seng Chua at the National University of Singapore on vision and language. |

|
|
I'm broadly interested in video and 3D vision, with the goal of making the agents perceive the physical world and reason based on its perception. I'm also excited to explore other interesting topics (such as generative models). |
|
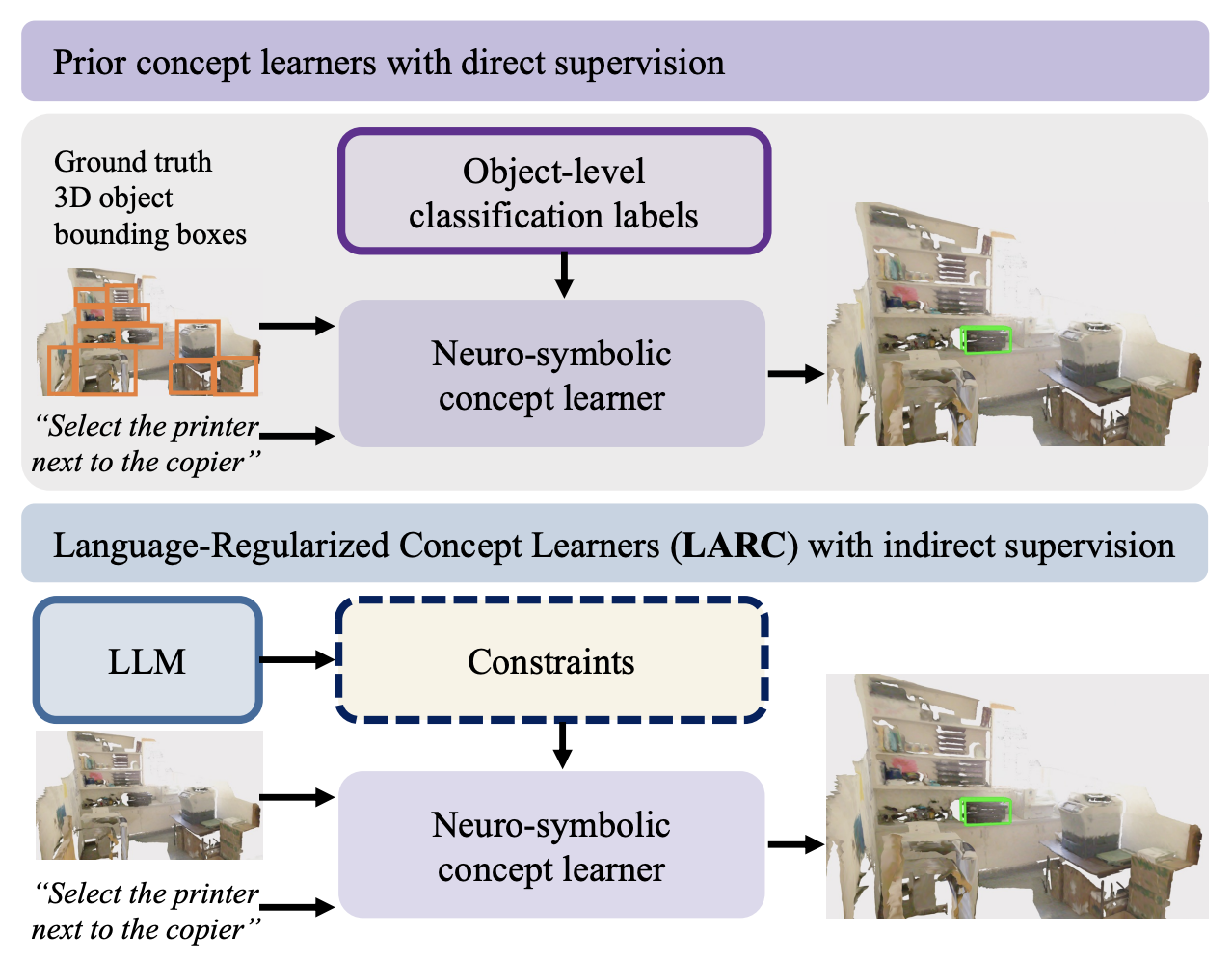
Chun Feng*, Joy Hsu*, Weiyu Liu, Jiajun Wu CVPR 2024 PDF / code / project page 3D visual grounding is a challenging task that often requires direct and dense supervision, notably the semantic label for each object in the scene. In this paper, we instead study the naturally supervised setting that learns from only 3D scene and QA pairs, where prior works underperform. We propose the Language-Regularized Concept Learner (LARC), which uses constraints from language as regularization to significantly improve the accuracy of neuro-symbolic concept learners in the naturally supervised setting. |

|
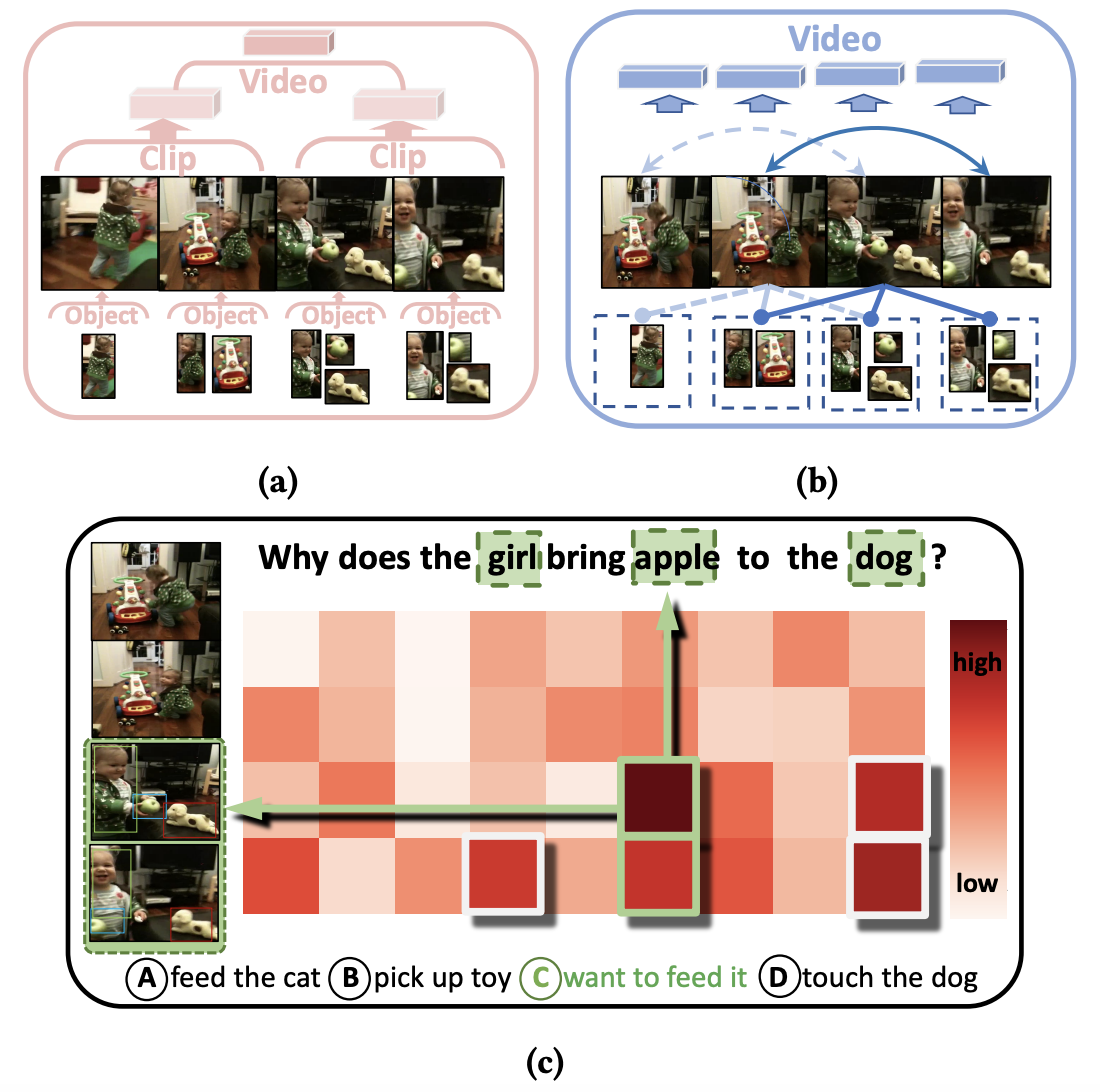
Yicong Li, Junbin Xiao, Chun Feng, Xiang Wang, Tat-Seng Chua ICCV 2023 arXiv / code We propose TranSTR that features a spatio-temporal rationalization (STR) module together with a more reasonable candidate answer modeling strategy. The answer modeling strategy is independently verified to be effective in boosting other existing VideoQA models. |
|
Yicong Li, Xu Yang, An Zhang, Chunfeng, Xiang Wang, Tat-Seng Chua ACM MM 2023 arXiv We propose RaFormer, a fully transformer-based VideoQA model that avoids neighboring-frame redundancy by highlighting object-level change in adjacent frames and the out-of-neighborhood message passing at frame-level. In addition, it also handles the cross-modal redundancy via a novel adaptive sampling module. |
|
Last updated: Feb 27, 2024 |